Jakiś czas temu w pracy dostałem zadanie uruchomienia modułu sprzętowego CRC na procesorze PIC32. W trakcie pracy wyszły pewne problemy, do rozwiązania których niezbędne było opanowanie teorii związanej z obliczaniem sum kontrolnych CRC. Zadanie to skłoniło mnie do dokładniejszej analizy problemu i podzielania się rezultatami w tym artykule.
CRC (Cyclic Redundancy Check) to kod o określonej z góry długości wygenerowany z ciągu danych wejściowych dodawany do oryginalnej wiadomości w celu zapewnienia integralności danych. CRC jest wykorzystywane między innymi do wykrywania przekłamań wiadomości przesyłanych przez łącza komunikacyjne, czy do sprawdzania poprawności danych zapisywanych na dysku. Zasada działania jest prosta. Nadawca (lub np. proces zapisujący dane na dysk) oblicza CRC dla wiadomości, którą chce wysłać i dodaje je do wysyłanych danych. Odbiorca (lub np. proces odczytujący dane z dysku) również oblicza sumę kontrolną danych, które otrzymał i porównuje ją z wartością CRC wysłaną przez nadawcę. Jeśli wyniki się różnią, doszło do przekłamania informacji.
Arytmetyka CRC
CRC jest algorytmem opartym na dzieleniu. Jest ono wykonywane za pomocą specjalnej arytmetyki różniącej się nieco od klasycznej. W arytmetyce CRC nie występują przeniesienia. Oznacza to, że dodawanie i odejmowanie są równoważne operacji XOR.
Dodawanie binarne:
1 + 0 = 1
0 + 0 = 0
1 + 1 = 10 -> normalnie najstarszy bajt wyniku przenieśli byśmy do dodawania kolejnego bajtu, ale przy obliczaniu CRC tak nie robimy i zostaje 0.
Odejmowanie binarne:
1 – 1 = 0
1 – 0 = 1
0 – 1 = -1 -> normalnie byśmy przenieśli 1 ze starszego bajtu i dostali 10 – 1 = 1, i starszy bajt zmniejszony o 1, przy obliczaniu CRC nie zmniejszamy starszego bitu i zostaje 1.
Wielomiany CRC
Dzielenie CRC jest zbliżone do dzielenia wielomianów, gdzie zależność między kolejnymi potęgami nie jest znana, dlatego nie można stosować przeniesień. Wielomian jest zapisywany jako liczba binarna. Stopień wielomianu odpowiada liczbie bitów, a kolejne bity oznaczają następne potęgi. Jeżeli bit wynosi 1, potęga wchodzi w skład wielomianu, jeśli 0 – nie. Najwyższy bit zawsze wynosi 1 i jest pomijany w binarnej reprezentacji wielomianu.
Przeanalizujmy to na przykładzie. Mamy liczbę szesnastkową 0xA, w reprezentacji binarnej to 1010. Mamy więc 4 bity, czyli stopień wielomianu to 4. Najwyższa potęga zawsze wynosi 1 i nie jest zapisywana w reprezentacji binarnej. Na początku wielomianu mamy więc 
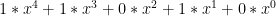
Wielomian CRC (w angielskiej nomenklaturze CRC poly) to wielomian przez który dzielimy dane wejściowe w algorytmie CRC. Dla różnych wielomianów sumy kontrolne dla tych samych danych wejściowych są różne.
Obliczanie CRC
Dzielenie CRC jest dosyć podobne do dzielenia pisemnego. Najłatwiej będzie to przedstawić na przykładzie. Weźmy ciąg danych 0xA53(binarnie 101001010011) i wielomian 0x6(binarnie 0110). Do ciągu danych dopisujemy tyle zer ile bitów jest w naszym wielomianie. Musimy więc dopisać 4 zera otrzymując 1010010100110000. Do wielomianu dodajemy 1 na najstarszym bicie otrzymując 10110. Możemy teraz przystąpić do dzielenia pisemnego. Dzielenie przedstawiłem jako kod źródłowy. Po prawej stronie opis co aktualnie się dzieje. Opis trochę wychodzi poza widoczne okno, dlatego trzeba scrollować na boki. Nie chciałem przenosić opisów do kolejnych linii, żeby dobrze było widać dzielenie. Mam nadzieję, że taka forma przedstawienia treści będzie wystarczająco czytelna.
100100111010 ---------------- 1010010100110000 : 10110 //bierzemy 5 pierwszych bitów dzielnej, pierwszy bit to 1, więc dopisujemy 1 do wyniku i pod spodem zapisujemy dzielnik 10110 //wykonujemy odejmowanie czyli XOR ----- 00101 //dopisujemy kolejną cyfrę z dzielnej na koniec, najwyższy bit to 0, więc dopisujemy 0 do wyniku i pod spodem zapisujemy 0 00000 //wykonujemy XOR ----- 01010 //to samo co poprzednio 00000 ----- 10101 //pierwszy bit to 1, więc dopisujemy 1 do wyniku i pod spodem zapisujemy dzielnik 10110 //wykonujemy XOR ----- 00110 //Powtarzamy aż dojdziemy do ostatniego bitu dzielnej 00000 ----- 01100 00000 ----- 11001 10110 ----- 11111 10110 ----- 10010 10110 ----- 01000 00000 ----- 10000 10110 ----- 01100 00000 ----- 1100 //Reszta po dojściu do ostatniej cyfry dzielnej to nasza suma CRC dla zadanych danych wejściowych i wielomianu.
Przedstawiony algorytm można zaimplementować, ale będzie on bardzo powolny ze względu na operacje na każdym bicie z osobna. W dalszej części artykułu opiszę, jak przyspieszyć obliczenia na procesorze.
Algorytm z użyciem lookup table
Dla każdego bitu dzielnej reszta jest XORowana z wielomianem albo z zerem. Oznacza to, że dla zadanego wielomianu i każdej możliwej kombinacji k pierwszych bitów danej możemy wyznaczyć wartość, jaką należy zXORować z resztą. Wartości te możemy obliczyć wcześniej i umieścić w tablicy (lookup table), żeby algorytm z nich korzystał. Dla stopnia wielomianu n i ilości bitów danej k (w praktyce stosuje się wyłącznie k=8 aby działać na pojedynczych bajtach) pojedyncza iteracja algorytmu będzie miała postać:
val = remainder >> (n-k); //weź k najstarszych bitów reszty remainder = (remainder << k) | data; //przesuń resztę o k bitów i dodaj nowe bity danych remainder ^= lookup[val]; //oblicz nową resztę na bazie tablicy lookup
Ten algorytm nosi nazwę Indirect CRC. Taka implementacja ma jednak pewną wadę. Jak pamiętacie z poprzedniego rozdziału, gdzie liczyliśmy CRC pisemnie, do danych trzeba było dodać na końcu zera. Tutaj również należy dodać na końcu zera i wykonać dla nich dodatkowe iteracje, żeby wszystkie bajty danych przeszły całe dzielenie. Okazuje się, że można zmodyfikować algorytm tablicowy tak, żeby nie trzeba było dodawać zer.
val = (remainder >> (n-k))^data; remainder = (remainder >> k) ^ lookup[val];
Ten algorytm nosi nazwę Direct CRC.
Modyfikacje algorytmu
Algorytm CRC we wszystkich przedstawionych powyżej wariantach nie radzi sobie dobrze z danymi wejściowymi składającymi się z samych zer, albo posiadających zera na początku. W pierwszym przypadku suma kontrolna wyniesie 0. W drugim – taka sama suma zostanie wygenerowana dla tych samych danych wejściowych poprzedzonych różną ilością zer. Czyli na przykład 0x0000AAAABBBBCCCC będzie miało taką samą sumę kontrolną, jak 0xAAAABBBBCCCC. Żeby wyeliminować ten problem, stosuje się seeda, czyli początkowa wartość zmiennej przechowującej resztę z dzielenia jest inicjowana jakąś niezerową wartością.
Aby uzyskać ten sam wynik, należy podać innego seeda do algorytmu Direct, niż do Indirect. Aby seeda Indirect przekonwertować na Direct, należy uruchomić algorytm Indirect na ciągu danych o długości wielomianu składającym się z samych zer i z podanym seedem, który chcemy przekonwertować. Konwersji w drugą stronę można dokonać robiąc bit po bicie operację odwrotną do dzielenia CRC, jak w kodzie poniżej:
uint32_t seed_direct2indirect(uint32_t poly, uint32_t direct)
{
int32_t i;
uint32_t reg = direct;
for (i = 0; i < CRC_SIZE; i++)
{
if (1 == (reg & 0x00000001))
{
reg = reg ^ poly;
reg >>= 1;
reg |= 0x80000000;
}
else
{
reg >>= 1;
}
}
return reg;
}
Przykłady konwersji seedów między dwoma typami algorytmu można znaleźć w kodzie, który udostępniłem na GitHubie – link w rozdziale Implementacja CRC.
Inną częstą modyfikacją algorytmu jest dodanie operacji XOR na końcowym wyniku z pewną stałą. Czasem również odwracane są bity w kolejnych bajtach danych wejściowych i w zwracanym wyniku.
Wybór wielomianu
Sumy CRC dla różnych ciągów danych powinny przyjmować różne wartości z równo rozłożonym prawdopodobieństwem. Poza tym niewielka zmiana ciągu wejściowego powinna powodować znaczącą zmianę sumy kontrolnej. W ten sposób zapewniamy lepszą ochronę przed kolizją, czyli takim przekłamaniem wartości, które daje tą samą sumę kontrolną. Do tego celu najlepiej używać wielomianów o odpowiednich właściwościach. Najlepiej wybrać jeden z popularnych wielomianów wykorzystywanych w istniejących protokołach takich jak Modbus, czy Ethernet. Na anglojęzycznej Wikipedii można znaleźć listę popularnych wielomianów: https://en.wikipedia.org/wiki/Cyclic_redundancy_check#Standards_and_common_use
Generowanie tablicy lookup
Aby wygenerować samemu tablicę lookup, należy wziąć każdy możliwy ciąg bitów o zadanej długości (np. 8 bitów dla tablicy o 256 elementach), dopełnić go zerami do długości wielomianu i wykonać na otrzymanej liczbie dzielenie CRC. Link do kodu generującego lookup table można znaleźć w rozdziale Implementacja CRC. Jeżeli chcemy skorzystać z gotowej tablicy, w internecie można znaleźć skrypty generujące tablice online.
Implementacja CRC
Aby pokazać działanie przedstawionej tutaj teorii w praktyce, postanowiłem napisać bibliotekę CRC posiadającą następujące funkcje:
- Obliczanie Direct i Indirect CRC.
- Generowanie lookup table.
- Konwersja seeda z Direct na Indirect.
- Wybór długości wielomianu – maximum 32.
- Odwracanie bitów na wejściu.
- Odwracanie bitów na wyjściu.
W projekcie zawarłem plik main.c prezentujący funkcje biblioteki – generowanie lookup table, obliczanie metodą direct i indirect oraz konwersja seedów pomiędzy obiema metodami. W pliku crc.h znajdują się definy, którymi można zmieniać długość wielomianu oraz obracać bity na wejściu i na wyjściu z funkcji obliczającej CRC. Ewentualne XORowanie wartości końcowej nie jest robione w funkcji bibliotecznej, należy je samemu przeprowadzić na otrzymanym wyniku. Kod źródłowy można znaleźć na GitHubie pod adresem: https://github.com/ucgosupl/crc
Na koniec – wracając do sprzętowego bloku CRC Microchipa. Jest on zaimplementowany na bazie LFSR (Linear Feedback Shift Register) i realizuje Indirect CRC. Oznacza to, że aby uzyskać rezultat zgodny z Direct CRC, należy użyć przekonwertowanego seeda i dodać na końcu wiadomości zera. Oczywiście nie znajdziemy tej informacji w dokumentacji.
19 września 2017 at 10:35
bieżemy -> bierzemy
19 września 2017 at 22:59
Dzięki
28 maja 2018 at 23:03
Bardzo przejrzyście zostało tu wytłumaczone obliczanie CRC. Dziękuję autorowi za ten artykuł 🙂